Let’s say you have a file around 1 GB in size containing just a little more than 10 million and 300 thousand lines of plain text data. Your goal is to extract the first 10 million lines and write those to another file. You figure an easy way this can be done is using PowerShell, so you enter the following command:
gc .\bigfile.txt -TotalCount 10000000 > lines-10M.txt
This takes a few minutes (it might not be the most efficient way of doing it), but in the end it gets the result just fine. Except… it seems the result file, which contains a strict subset of the data from the original file, has somehow grown to a full 2 GBs in size. How did that happen? There’s less data, and yet the file is almost twice as big!
Reading back the data from both files (using PowerShell’s Get-Content or .NET’s StreamReader) suggests the content from both files is identical up to the first 10 million lines. The files are too big to be opened by WinDiff or Notepad++ for viewing directly, but when we open them in HxD and place them side-by-side we can immediately identify the culprit:
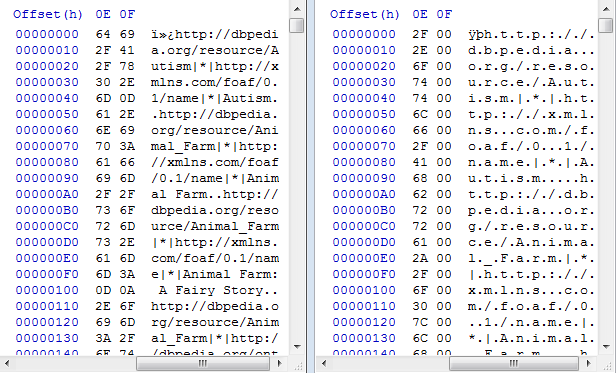
Ahh, character encodings. As you can clearly see in the screenshot above, the original file uses a single byte per character for encoding, while the file produced by PowerShell uses 2 bytes for each character. And indeed, further investigation learns us that by default PowerShell encodes text that it pipes to a file in UCS-2. This would account for the file size doubling, as we are encoding the same data using twice as much bytes to do so.
So alright, now that we know what the problem is, how do we fix it? Well, that’s all surprisingly easy, actually:
gc .\bigfile.txt -TotalCount 10000000 | Out-File -Encoding UTF8 .\lines-10M.txt
Rather than using the redirect-to-file operator (which is just syntactic sugar for Out-File anyway), we pipe to Out-File directly and specify the desired encoding as one of its parameters. And what do you know, suddenly the output produced is twice as small.